Re-thinking decision-support modelling -- a technical summary of the IAHR webinar on PEST

Lecture by: Prof. John Doherty
Technical Summary by: Dr. Xin He
The IAHR Webinar on Decision Support Modelling and PEST was organized by the IAHR Technical Committee on Groundwater Hydraulics and Management on May 20, 2021, with a lecture given by Prof. John Doherty, the author of PEST, a software package that is widely used for groundwater model calibration and uncertainty analysis. Below is a technical summary written by Dr. Xin He, who participated in the webinar and is a leadership member of the technical committee. For more details about this webinar, please go to the Related Event at the end of this page.
We learned experience from the past that models were used in order to help people make decisions about how to manage groundwater systems, e.g., first, in agricultural areas, sustainability of irrigation and allocation of water for the following year is estimated based on current groundwater levels; second, in mining areas, quantity of pumping is calculated for dewatering; third, in cleaning up of groundwater contamination, remediation systems are assessed for whether a plume can be captured by a certain disposition of wells.
When we have a groundwater model, in many cases a calibrated model, where a lot of money is paid, as the basis for making important decisions, it doesn't really serve the decision-making purpose. Examples show when we make predictions using a perfectly calibrated model with very few observed data, the results can still be very wrong. But does it make the model a bad model?
This is where we need to re-think decision support modeling. There is no mathematical argument that just because we get a few measurements embodied, the model can give the correct prediction. What can be mathematically justified is that the prediction is within the uncertainty limit that we can quantify through modeling. Therefore, modeling is in fact about quantify and reduce uncertainty. The current way of doing modeling is too complex, too expensive, and does not serve this purpose very well.
The reason why we turn to modeling is usually that someone wants to manage a system, which means they wouldn't take actions regarding how that system is managed, actions that do not lead to the happening of bad things. Therefore, in short, management is all about avoiding bad things. Our job, as modelers, is to give some probability to inform the decision makers of the probability that something will go wrong, considering all information. That way, when a decision maker makes a decision, he or she can take into account the risks associated with a certain course of management action.
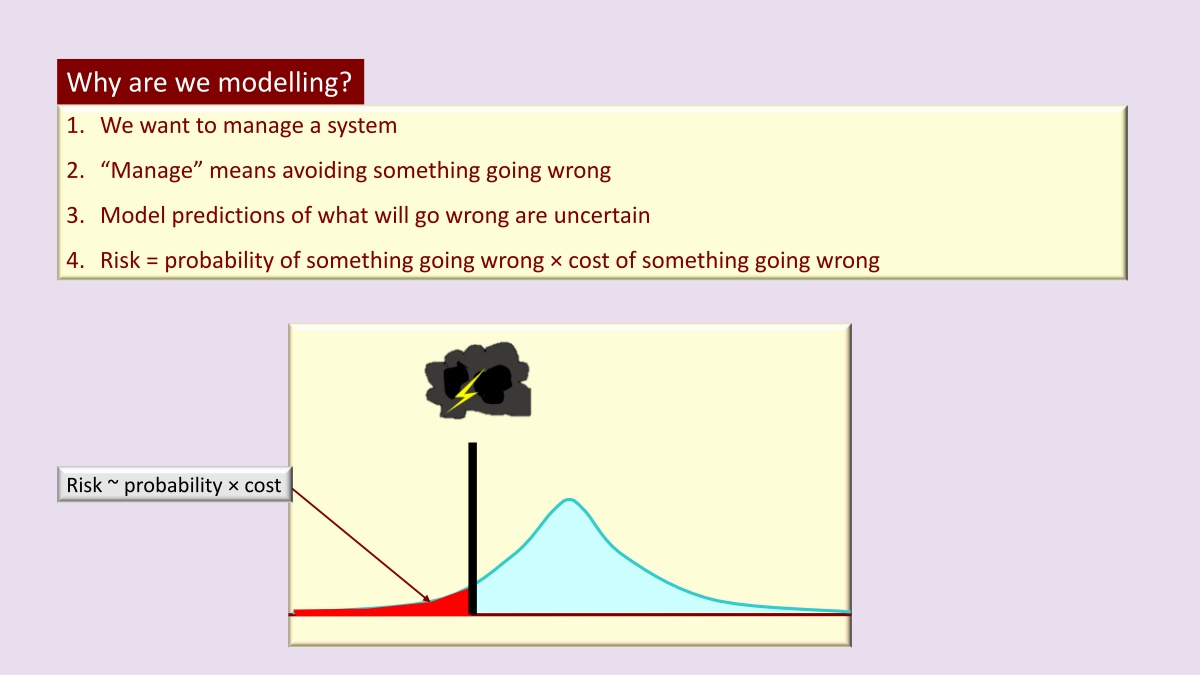
Risk can be defined loosely as the probability of something going wrong, times the cost of something going wrong. Determining costs is the decision-maker's job. Our job is to provide the uncertainty, and to allow decision makers to incorporate risk into the decision-making process in our industry, namely an assessment of the probability that something will go wrong. That is to say the greater goal is risk assessment. Unless this greater goal is part of how we build the model, from the very beginning of the modeling process, we're not doing it probably.
Information, by definition, is something that can reduce uncertainty. A model is useful not because we simulated it very well, but because we facilitated the flow of information, information from wherever it resides, to the predictions, on which decisions rest.
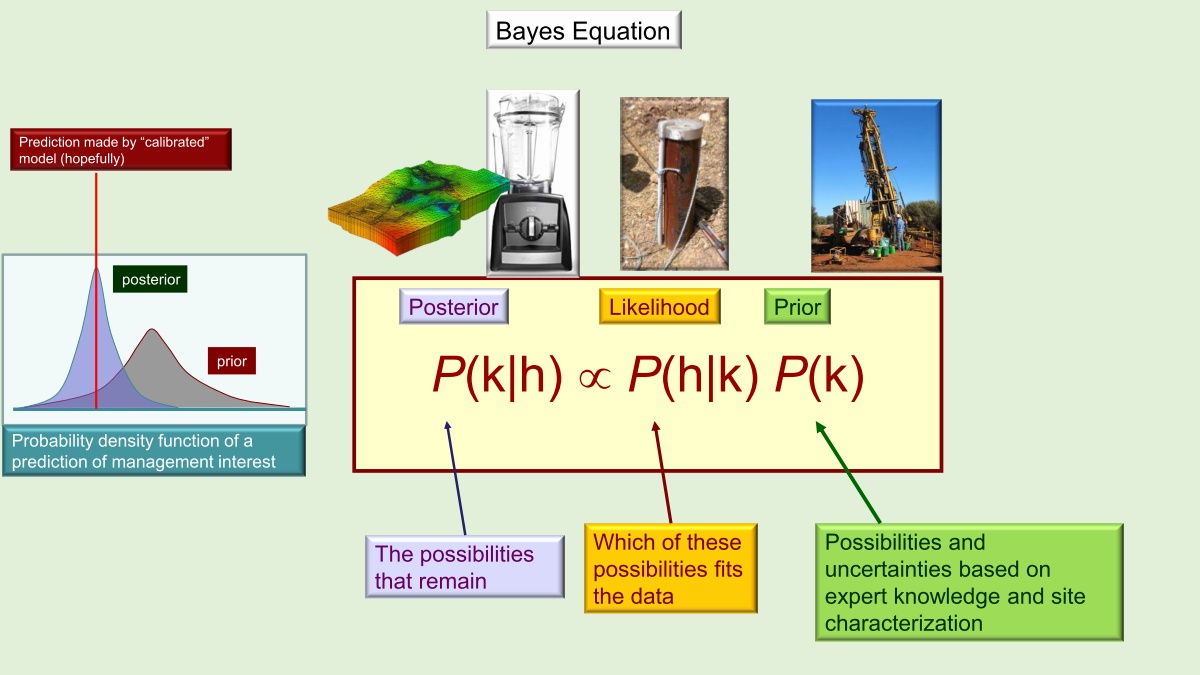
The classic Bayes equation has three parts:
Prior, is the information you know beforehand. In groundwater modeling, it is usually the drilling of boreholes, geological mapping, measurements of hydraulic properties, etc. Then we interpret between what we know to a three dimensional heterogeneous subsurface.
Likelihood, is how the prior information you know fit the data. In groundwater modeling, it is most likely the heads we measure in wells.
Posterior, the information we get after merging prior probability and likelihood.
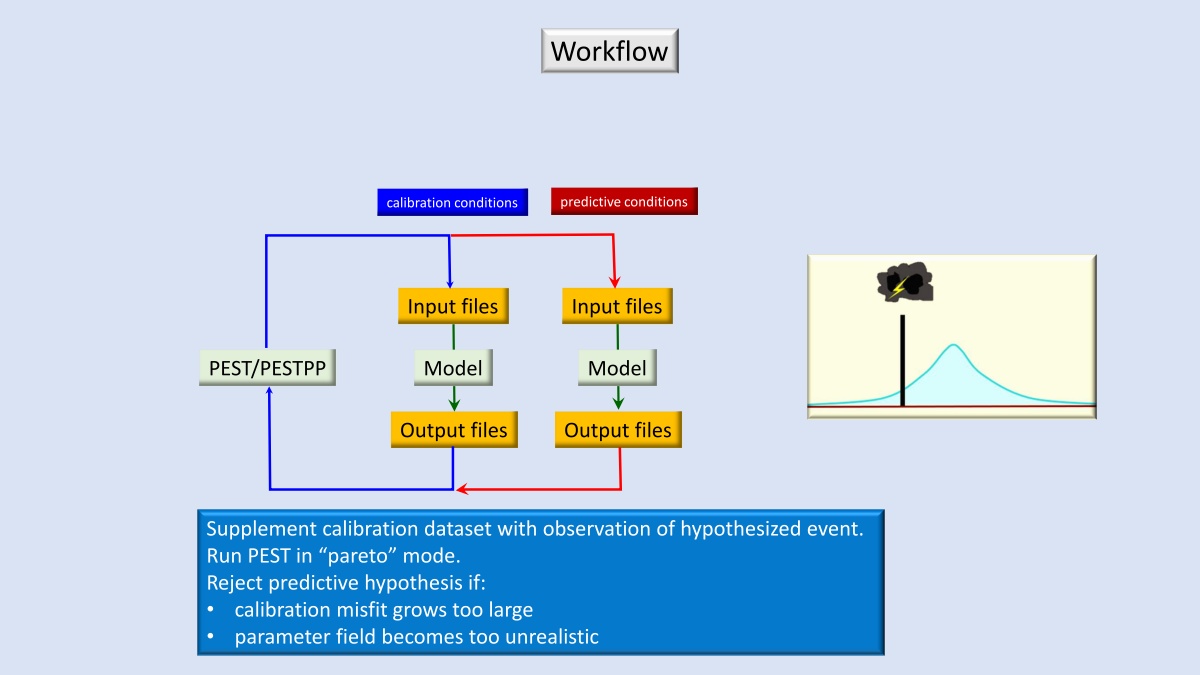
Simulation should serve Bayes equation, not the other way around. Then where does the calibrated model fit into this? The calibrated model is a convenient way of testing the hypothesis that whether our model is a worthy simulator of processes underground. If we do everything correctly, the predictions made by the calibrated model hopefully will lie somewhere near the center of the posterior probability distribution of those predictions.
In the old days, we were often told, don't use any more parameters than you need to calibrate the model. But these days, it's different. We need to live in a highly parameterize world. The reasons are: Firstly, having lots of parameters doesn't cost us very much at all with modern technology. Secondly, we need to have enough parameters to differentiate between the true heterogeneity where it needs to be introduced, and false heterogeneity, where there's no information about.
A model is essentially a simulator, and a simulator on its own cannot implement Bayes equation, thus a model on its own does not support decision making. This is why we need a tool like PEST. PEST have a non-intrusive interface with the model, which means it does not need to access the model source code. To work with PEST, your model should be able to run fairly fast and meanwhile numerically stable.
In conclusion, the idea that we build one giant, complex model that can make any kind of prediction no longer work. It's all about building a model from the ground up to implement Bayes equation, using it to assimilate whatever information is at hand to quantify and reduce the uncertainties of critical predictions. It will normally mean a model that has a lot of parameters, but possibly housed in a structure that's comparatively simple. We need to allow that model to run fast and show us through the parameter fields emerged through the history matching process. Not a picture-perfect representation of what's under the subsurface, but a lot of information about what is under the subsurface that will allow us to see what we can know, and what we cannot know, what implications we are able or not able to draw about what will happen to a system.
Related Event
2021-05-20